Static Site - Dynamic Data
How I solved a static site problem with a GitHub Actions 'stats crawler' middle-man.
I ran into an annoying limitation with my portfolio site recently. It’s fully static (GitHub Pages) by design. There is no backend, no server, etc. This is great for cost and simplicity, but not so great when you want live stats for your projects and blog.
I wanted my site to display things like:
- GitHub stars for each that had a linked repository
- Docker Hub pulls for each project that had a linked image
- Blog post view counts (from Google Analytics)
Fetching these directly from the user's browser turned into a mess pretty quickly.
Problem
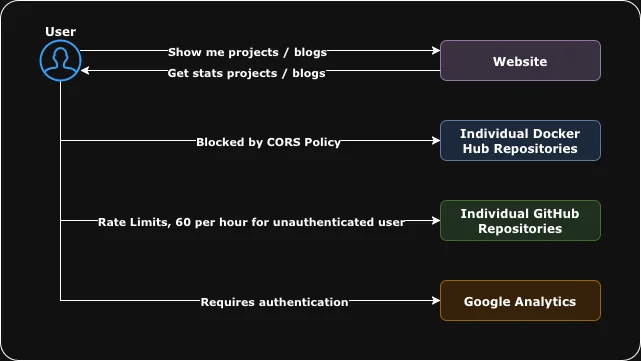
Because the site is static, everything had to happen client-side. That brought a few issues:
- GitHub: unauthenticated API requests are hard-limited to 60/hour per IP. With enough projects or refreshes, the star count endpoint would sometimes just fail.
- Docker Hub: strict CORS rules made direct browser calls impossible. The only option was a slow third-party CORS proxy (allorigins).
- Google Analytics: obviously can’t be queried client-side at all due to lack of authentication.
GitHub and Docker Stats would load sometimes, fail randomly, and were slow to show up. Blog views were not possible. This was not sufficient for a Developer / DevOps portfolio.
Solution
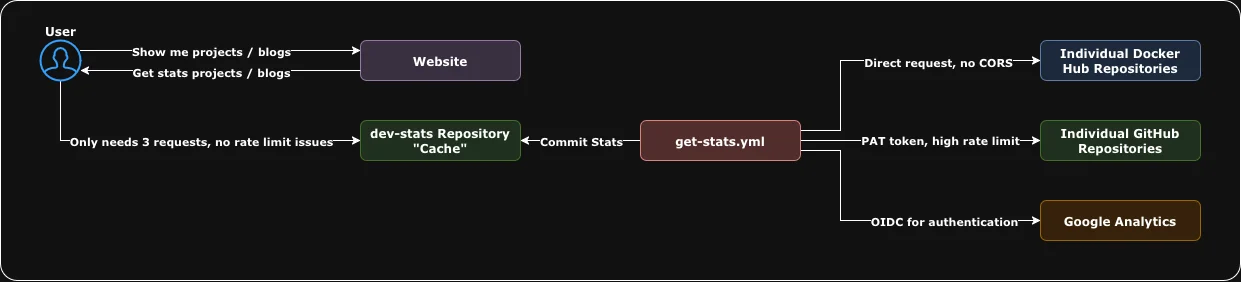
Instead of hitting these APIs from the browser, I built a separate repository that acts as a scheduled “stats crawler” / "cache" for the data I wanted. Think of this as our new CORS proxy.
Every 6 hours, a GitHub Actions workflow runs three Python scripts:
- fetch-dockerhub-stats.py: fetches all repos under my namespace and their pull/star counts
- fetch-github-stats.py: fetches stars, forks, watchers, open issues for all my repos
- fetch-google-analytics-stats.py: queries the Google Analytics project for total views on each blog post, authenticates via OIDC so no creds are stored in the repoitory
Each script writes the output to a JSON file and commits it back to the repository.
Then, on the client side, my portfolio only needs to request three static JSON files, no rate limits, no CORS issues, no leaking credentials.
So instead of:
N requests per project/blog post, often failing, sometimes rate limited, sometimes proxied.
I now have:
3 cheap, static GET requests served from GitHub’s CDN
This solved all the problems in one shot. The site loads faster, the numbers are consistent, and I don’t need to run or pay for a backend just to aggregate a few counters. Plus I've got statistics tracked over time in the form of git history.
Why Not Add a Simple Backend?
I considered spinning up a tiny endpoint in FastAPI or Cloudflare Workers, but even the cheapest option still meant adding ongoing hosting, monitoring, authentication, rate-limiting, etc.
With the GitHub Actions approach, the “backend” is basically free and maintenance-free. The data stays fresh enough for a personal site, and GitHub handles the scheduling.
Result
The result is my same free to host static website, now with flashy dynamic statistics included.