Projects
HomeLab
Self-Hosted Linux Servers with Secure Public Access Ongoing

Overview
As someone with a long-running history as a tech fanatic, I spend a large amount of money on services. From gaming servers for my friends and I, to document hosting via Google Drive, even my streaming services like Netflix or Hulu. This project aimed to replace these ongoing subscriptions with one time equipment purchases, and host my own data and services from the comfort of my own home.
What do I Run?
- DNS Server
- SSO Provider
- Internal VPN
- Reverse Proxy
- Network Monitor
- NFS Backup System
Docker Compose
With the exception of my VPN, all the services I host are ran and managed through Docker Compose files. The reasoning for this is twofold.
- First, Docker Compose files make service organization a breeze and help prevent the looming threat of tech debt. All of my compose files are kept in a neat directory and backups are stored on my GitHub. Should anything happen to my servers, all configuration is maintained and can be replaced in a heartbeat.
- Second, there is added security offered through the principle of least privilege. Each Docker container is granted specific access to the files and directories they need, which are mounted as root folders within the container. This helps mitigate scope change should an unidentified vulnerability in a service be exploited.
Wireguard VPN
Not all services are created equally, and not all services should be exposed publicly. There is however something to be said for having admin access to your services from anywhere in the world. To solve this, one of my Raspberry Pi's runs a Wireguard VPN that accepts two clients; the first is my phone and the second is my laptop, both of which have their own individual key.
SSO Authentication
By hosting a service called Authentik, I gain access to an SSO with integrated 2-factor authentication. Authentik provides the means for many authentication methods including SAML, LDAP, and Radius. Many self-hosted services do not support any sort of authentication protocols, so for these I run Authentik as a reverse proxy, prohibiting the proxying of any service to unauthenticated users.

MythicMate
An AI Powered Dungeons and Dragons Companion Nov 2023

Overview
My friends and I got into playing the Table Top Game, Dungeons and Dragons a few years ago, and it has been one of the main reasons that we have been able to stay in touch as people have begun to move away from home. As the distance between us spread, we had to move from meeting in person to playing on Discord, and the resources are lacking. There are dice rolling bots out there, but they are very specific with input, there are information bots out there, but they require paid accounts to use, I decided to use my skills to my advantage and make what we had all been wanting. A simple, easy to use, highly functional D&D Companion: MythicMate
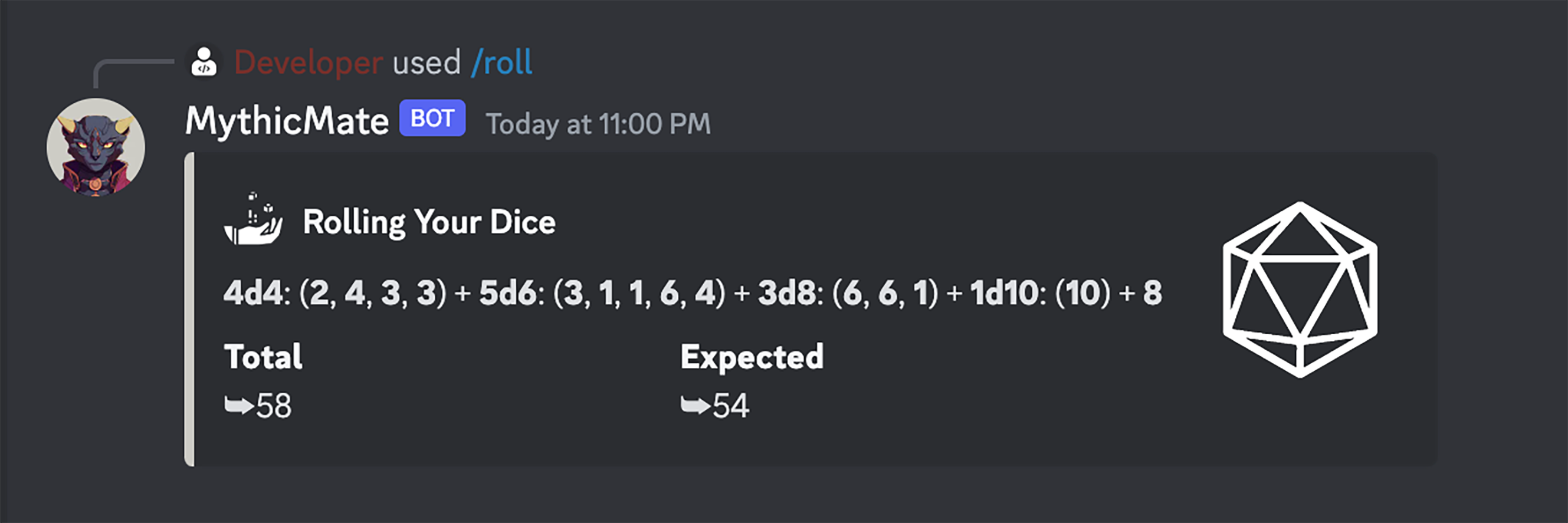
Dice Rolling
When you are in the middle of a game, you don't want to have to remember the complex syntax of commands, or worry about a misspelling ruining your flow, you want fast and effective. For the dice rolling commands, MythicMate accepts any length of dice, and displays what each one rolled for dramatic effect. It sorts through your input with regex, and if the bot for some reason does not recognize a symbol, it will still roll your dice and alert you of the error! No more pausing to ask "How do I roll again?"
Web Scraping
A lot of D&D content is locked behind a paywall, but there are user ran sites like the DND5eWikiDot, that you can gather the important things from like rules, and spell details. When I run the update command, it searches this wiki, and pulls the relevant information from it, saving it as text files formatted in Discords markdown on my computer. When a user wants to look up something, it references the available text files, and offers autocomplete suggestions. The files are then simply passed into a discord message with no further formatting needed, because it is all taken care of when scraping the data. This results in lightning fast searches.
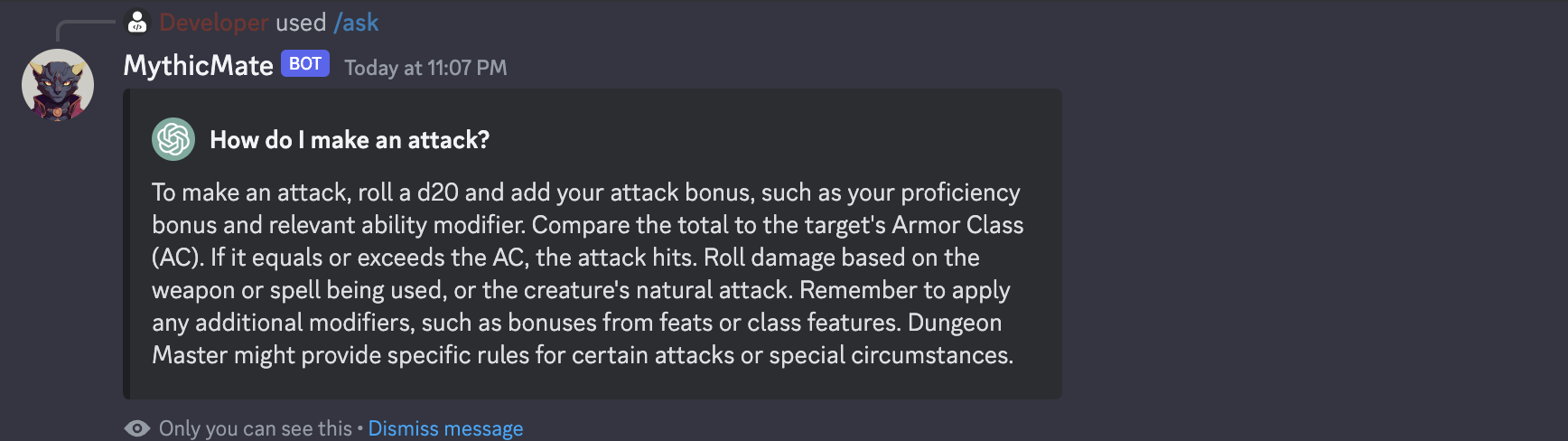
AI Integration
While a lot of information about D&D is locked behind a paywall, even more of it is scattered across random iterations of rule books, and source material. Utilizing ChatGPT's interface, and precise preformatted instruction, I have created the "/ask" command. The user simply types "/ask" and then their question, and my bot accesses the API and runs a formatted request. The answer is then quickly returned in a message for them.
Multithreaded Implementation
A Discord bot with AI integration is great until you realize the processing delays involved with AI, specifically ChatGPT's API. When one user had a hanging request for an AI generated rules check, no other user was capable of running commands. To solve this I implemented multithreading, allowing each command to create and run on a new thread as soon as it is called, keeping the main bot free to process incoming commands.
Featuring
A Spotify Data Analysis Project Dec 2024
Overview
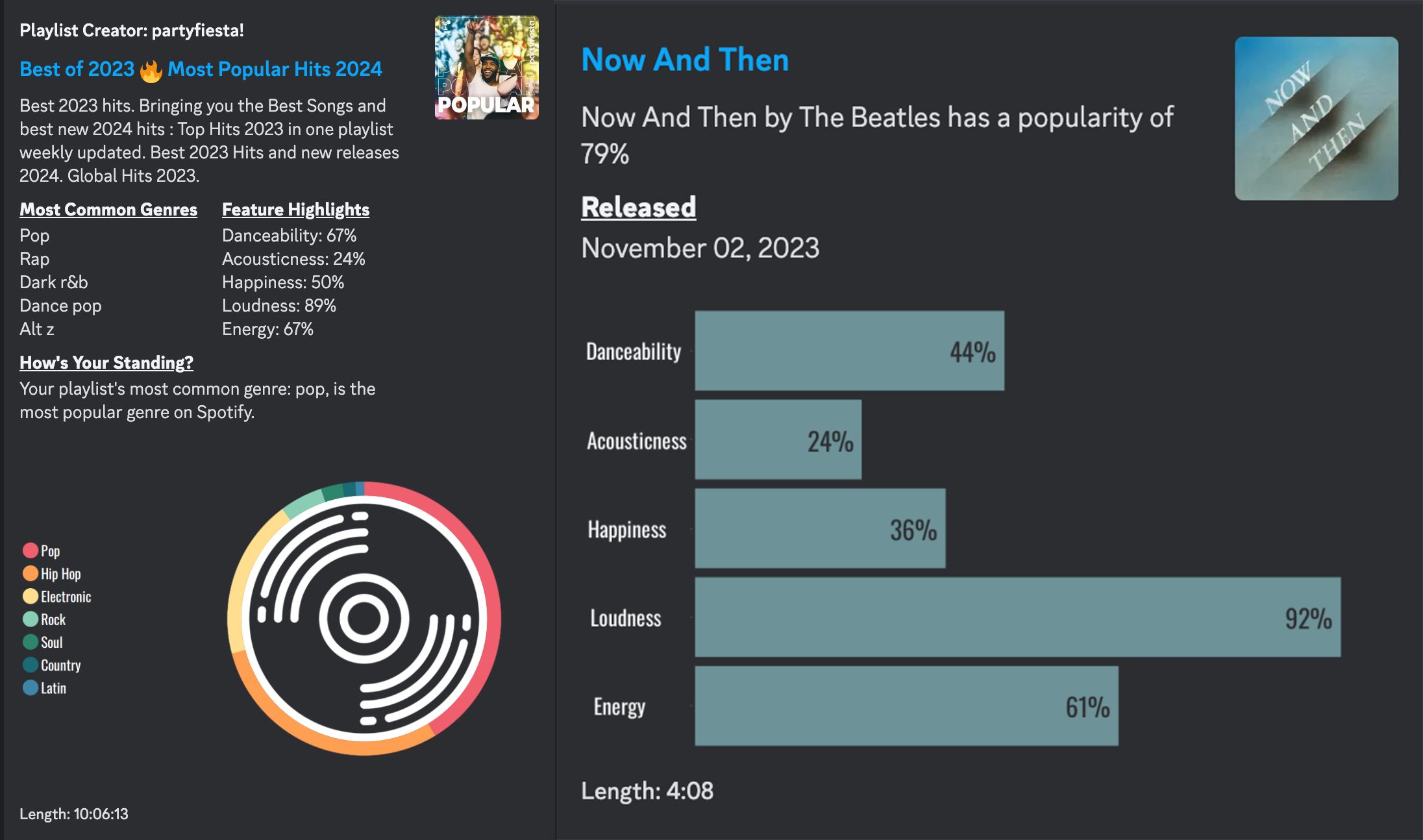
Featuring was an idea inspired by the immense number of genres that spotify's algorithms classify (there is over 5000) that we as Spotify listeners are unable to access. Spotify stores a lot of information about songs, such as the "danceability" of the song, or the "energy" of the song. To music lovers like myself, information like this is fascinating, and I wanted to provide other listeners with the statistics Spotify keeps hidden behind their API.
Digestable Data
Telling you that your music has a danceability of 0.86, or that 1% of your music is considered Ectofolk (yes that is a real Spotify genre) does not do much on its own, the data needed to be easy to digest. To accomplish this, I heavily manipulated an open source Java addon called JFreeChart in order to achieve the visually appealing, and easy to understand graphs that Featuring presents to users.